This is in response to the blog post by Sylvain Kerkour benchmarking ring and Rust Crypto AEADs. I was curious how HACL* stacks up to these two with these parameters.
I’m maintaining the Evercrypt crate, a wrapper around the formally verified crypto library HACL*. HACL* is a customizable, fast, formally verified crypto library written in F* and extracted to C.
Results
I’m listing all results here for comparison as I’m (obviously) running the benchmarks on a different machine.
| 100B | 1kB | 100kB | 1MB | 10MB | 100MB | 1GB | |
|---|---|---|---|---|---|---|---|
| RustCrypto’s ChaCha20-Poly1305 v0.8.2 | 1.6232 us (58.753 MiB/s) | 2.6941 us (353.98 MiB/s) | 120.10 us (794.10 MiB/s) | 1.1921 ms (800.02 MiB/s) | 12.015 ms (793.75 MiB/s) | 119.87 ms (795.58 MiB/s) | 1.1947 s (798.27 MiB/s) |
| RustCrypto’s AES-256-GCM v0.9.4 | 448.97 ns (212.42 MiB/s) | 1.5090 us (632.01 MiB/s) | 118.13 us (807.33 MiB/s) | 1.1947 ms (798.24 MiB/s) | 11.986 ms (795.68 MiB/s) | 119.39 ms (798.81 MiB/s) | 1.1974 s (796.43 MiB/s) |
| ring’s ChaCha20-Poly1305 v0.16.20 | 193.82 ns (492.04 MiB/s) | 730.23 ns (1.2754 GiB/s) | 48.293 us (1.9285 GiB/s) | 490.64 us (1.8982 GiB/s) | 5.0475 ms (1.8451 GiB/s) | 51.438 ms (1.8106 GiB/s) | 514.99 ms (1.8084 GiB/s) |
| ring’s AES-256-GCM v0.16.20 | 235.57 ns (404.83 MiB/s) | 556.64 ns (1.6731 GiB/s) | 34.609 us (2.6910 GiB/s) | 343.41 us (2.7120 GiB/s) | 3.5471 ms (2.6256 GiB/s) | 34.873 ms (2.6706 GiB/s) | 348.51 ms (2.6723 GiB/s) |
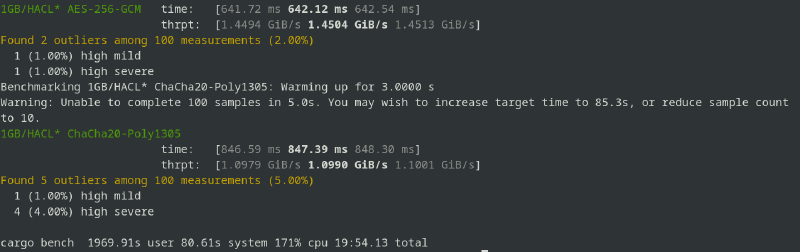
| HACL*’s ChaCha20-Poly1305 v0.0.10 | 862.79 ns (110.53 MiB/s) | 1.2804 us (744.81 MiB/s) | 55.550 us (1.6765 GiB/s) | 549.11 us (1.6961 GiB/s) | 5.8844 ms (1.5827 GiB/s) | 88.801 ms (1.0488 GiB/s) | 847.39 ms (1.0990 GiB/s) |
| HACL*’s AES-256-GCM v0.0.10 | 238.12 ns (400.51 MiB/s) | 598.56 ns (1.5560 GiB/s) | 38.997 us (2.3882 GiB/s) | 391.87 us (2.3766 GiB/s) | 4.0217 ms (2.3157 GiB/s) | 68.004 ms (1.3695 GiB/s) | 642.12 ms (1.4504 GiB/s) |
It is interesting to see that the HACL* AES-256-GCM implementation is only slightly slower than ring’s (2.3GiB/s vs 2.7GiB/s) for 1MB and 10MB chunks. But it significantly drops in performance for larger blobs while ring’s performance stays the same. The picture for Chacha20Poly1305 is similar, which points to general issues of handling large data sizes within HACL*.
M1
My main machine right now is a MacBook with M1 chip. This is a very different machine. Here are the numbers.
Note that HACL* doesn’t support AES on ARM chips yet unfortunately.
| 100B | 1kB | 100kB | 1MB | 10MB | 100MB | 1GB | |
|---|---|---|---|---|---|---|---|
| [RustCrypto’s XChaCha20-Poly1305] v0.8.2 | 558.20 ns (170.85 MiB/s) | 3.0136 us (316.46 MiB/s) | 274.25 us (347.74 MiB/s) | 2.7434 ms (347.62 MiB/s) | 27.535 ms (346.35 MiB/s) | 279.16 ms (341.62 MiB/s) | 2.7657 s (344.83 MiB/s) |
| RustCrypto’s ChaCha20-Poly1305 v0.8.2 | 460.31 ns (207.18 MiB/s) | 2.9189 us (326.73 MiB/s) | 273.95 us (348.12 MiB/s) | 2.7429 ms (347.69 MiB/s) | 27.623 ms (345.25 MiB/s) | 281.35 ms (338.96 MiB/s) | 2.7525 s (346.48 MiB/s) |
| RustCrypto’s AES-256-GCM v0.9.4 | 3.0838 us (30.925 MiB/s) | 9.3825 us (101.64 MiB/s) | 707.99 us (134.70 MiB/s) | 7.0729 ms (134.83 MiB/s) | 70.655 ms (134.98 MiB/s) | 706.42 ms (135.00 MiB/s) | 7.1158 s (134.02 MiB/s) |
| ring’s ChaCha20-Poly1305 v0.16.20 | 407.12 ns (234.25 MiB/s) | 1.3175 us (723.85 MiB/s) | 96.781 us (985.40 MiB/s) | 963.70 us (989.60 MiB/s) | 9.6676 ms (986.46 MiB/s) | 98.252 ms (970.64 MiB/s) | 975.96 ms (977.17 MiB/s) |
| ring’s AES-256-GCM v0.16.20 | 79.751 ns (1.1678 GiB/s) | 394.01 ns (2.3637 GiB/s) | 34.355 us (2.7109 GiB/s) | 344.78 us (2.7012 GiB/s) | 3.4792 ms (2.6768 GiB/s) | 34.543 ms (2.6961 GiB/s) | 345.92 ms (2.6923 GiB/s) |
| HACL*’s ChaCha20-Poly1305 v0.0.10 | 690.43 ns (138.13 MiB/s) | 1.7545 us (543.55 MiB/s) | 132.59 us (719.25 MiB/s) | 1.3096 ms (728.24 MiB/s) | 13.261 ms (719.13 MiB/s) | 137.91 ms (691.53 MiB/s) | 1.4217 s (670.82 MiB/s) |
Ring’s performance is again great and very stable across different payload sizes. Rust Crypto’s implementations are significantly slower than ring’s again but also slower than on the Intel machine. The HACL* performance for Chacha20Poly1305 is again a little worse than ring’s but significantly better than Rust Crypto’s.
CPU Info
Intel
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i7-4900MQ CPU @ 2.80GHz
CPU family: 6
Model: 60
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
Stepping: 3
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 5589.60
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx f
xsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_
good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx e
st tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c
rdrand lahf_lm abm cpuid_fault epb invpcid_single pti tpr_shadow vnmi flexpriority ept vpid e
pt_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt dtherm ida arat pln pts
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 128 KiB (4 instances)
L1i: 128 KiB (4 instances)
L2: 1 MiB (4 instances)
L3: 8 MiB (1 instance)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-7
Vulnerabilities:
Itlb multihit: KVM: Mitigation: VMX disabled
L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable
Meltdown: Mitigation; PTI
Spec store bypass: Vulnerable
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Full generic retpoline, STIBP disabled, RSB filling
Srbds: Vulnerable: No microcode
Tsx async abort: Not affected
M1
machdep.cpu.brand_string: Apple M1
machdep.cpu.core_count: 8
machdep.cpu.cores_per_package: 8
machdep.cpu.logical_per_package: 8
machdep.cpu.thread_count: 8
The code changes needed for these experiments are on Github.